Working with Prompt Templates
Choosing & Creating Evaluation Metrics
We've created a prompt template, we have our tests - now we need to decide how to assess the response of the LLM models compared to our test cases' target outputs.
Libretto offers a wide variety of metrics based on the latest research available, and we're constantly adding more. We generally call these metrics "evals".
Overview
Each eval can be enabled by either selecting the relevant checkbox, or setting its toggle button to "Active" and saving its settings. There is no limit to the number of evals you can select, though some are more computationally intensive and may extend the length of test runs and Experiments.
When you see evaluation results throughout Libretto, they will often be presented as the average result across all of a prompt template's test cases.
Preprocessing
Libretto offers a couple of settings you can use to make sure the correct portion of the LLM response is evaluated appropriately. By default, we strip leading and trailing whitespace from a response, but it's pretty common to want to strip other parts of the LLM response. The most common use case we see is that effective prompts often ask the LLM to talk through a problem before outputting an answer in a well-known format. For example, you might have the following as an answer from an LLM prompt for doing math word problems:
Jane starts with 4 apples and gives 3 to Miguel, which means she has 4 - 3 = 1 apple. Then Lana gives her 5 apples, so she has 1 + 5 = 6 apples. So the answer is [[6]].
At the top of the Eval Settings page, you can add a regular expression to strip all of the reasoning out of the LLM response and just test the final answer. If the regular expression contains at least one matching group, then the contents of the first matching group will be extracted. If there are no matching groups, then the entire match will be extracted and the response will be unchanged.
Semantic Comparison
This set of evals consists of "scoring" systems that compare the words and sequence of the words used in a response, rather than the meaning of the content.
Format
Strict Output Comparison
This metric is as straightforward as it gets - does the outputted response from the LLM exactly match the content specified in the test case's target output? The content can be formatted as plain text, JSON, or a CSV.
The result is a binary Yes or No, but for a set of test cases, the results will be summarized as the percentage of test cases that do have an exact match.
N-Gram Overlapping
These evals evaluate the "quality" of the text by measuring the overlap of n-grams (a sequence of n words/numbers/symbols) between the target output and LLM response.
These results are given in percentages from 0% - 100%.
BLEU
The BLEU metric emphasizes precision, counting the number n-grams in the LLM response that are present in target output. It also provides a penalty if the output response is shorter than the target response.
As such, BLEU is often used for assessing the quality of translations.
ROUGE
Complementary to BLEU, the ROUGE score is actually a collection of metrics that focus on recall. Libretto currently uses ROUGE-L F1-score - this finds the longest shared n-gram between the target output and LLM response, calculates both the precision and recall scores between the two, and then combines them into a single metric.
ROUGE is a particularly valuable metric in assessing summarizations.
String Similarity
We currently have two evals in this category BERTScore and Cosine Similarity. These are less exact than the n-gram analysis in the previous category, and utilize the context AND content of words to derive a score based on how similar the LLM response is to the target output. The results are given in percentages of 0% - 100%.
Cosine Similarity
Technically speaking, cosine similarity converts the content of target and actual responses into vectors using embeddings, and then measures the cosine of the angle between them. Essentially, if a sequence of words can be broken down in meaning in the exact same way, they will have a cosine similarity of 1.
This is a good and efficient metric for how close the the response matches in meaning at a surface level, such as theme or information retrieval.
BERTScore
BERTScore provides a deeper semantic analysis of the context and the content for a given piece of text and language, and actually utilizes cosine similarity calculations in its processing. It can better capture synonyms, paraphrases, and linguistic quirks than other metrics might.
This is an excellent metric to choose for translations and summarization.
Subjective Evaluation
This group of evals leverage LLM's themselves to act as a judge and assess an LLM's response against a provided set of criteria.
Custom Open-ended Assessments
Categorization
Provide a list of possible outputs, and the LLM will attempt to provide a category output for a given input.
An example might be "The response should be only one of the following answers: Happy, Neutral, Sad."
Statement Veracity
Provide the LLM a certain statement, and the LLM will judge whether the statement holds true for a given input.
An example might be "The response should be professional" or "The response should not be malicious".
Factual Consistency
Provide the LLM with a given context and prompt, such as a reference document or blog post along with a statement or question. The LLM will create a list of factual statements for the combined context, as well as a list of general statements made by the LLM output. It will then calculate the percentage of statements in the LLM output that do not contradict any of the statements generated from the combined context.
A target output is not necessary for this eval.
Relevance
Similar to Factual consistency, given a context and prompt, the LLM will determine the percentage of statements in the LLM output that are deemed relevant to the prompt.
A target output is not necessary for this eval.
Scorecard
Defaulted to "Great", "Good", "Poor", and "Terrible", a separate LLM call will assess the initial LLM output and attempt to categorize the response into one of the aforementioned Scores.
For each Score, you can provide additonal guidance on what constitutes a corresponding response.
Classification
Utilizing neural network models, these evals take a set of labels for a given topic and provide a confidence level that the LLM output adheres to that label.
By default, we determine that a label is successfully matched (and display that label in any UI results) if the confidence level is great than 30%.
Toxicity
For each of these labels, this eval will output a confidence level that the LLM output matches a given label: Toxic, Severe Toxic, Obscene, Threat, Insult, and Identity Hate.
Language
Currently supporting 52 languages, this eval will provide a confidence level if the LLM response contains a certain language.
Emotion
For each of these labels, this eval will output a confidence level that the LLM output matches a given label: Remorse, Sadness, Love, Caring, Disappointment, Approval, Gratitude, Admiration, Grief, Optimism, Disapproval, Realization, Desire, Curiosity, Confusion, Anger, Embarrassment, Joy, Amusement, Disgust, Annoyance, Neutral, Nervousness, Relief, Fear, Excitement", Surprise, and Pride.
LLM-as-Judge
These evals provide the concept of using a highly capable LLM to assess the responses of another LLM. This idea is commonly referred to as "LLM-as-Judge," and is generally applied when an evaluation of open-ended criteria is warranted.
Each LLM-as-Judge eval has two parts:
- The criteria to judge.
- A scoring rubric for the assessment.
When the eval is run, an LLM will be prompted to assess the current test case output against the critieria, responding with a score from the rubric. For example, a prompt that creates riddles and their solutions could have the following LLM-as-Judge eval:
- Name: Riddle Difficulty and Relevance
- Criteria: Evaluates the riddle's ability to be challenging yet solvable, progressively guiding with hints while maintaining fairness and complexity suitable to the topic.
- Rubric:
- The riddle is overly simplistic or impossibly difficult with no guiding hints.
- The riddle has minor challenge but lacks sufficient guidance or complexity.
- The riddle is moderately challenging with some hints but may lack fair progression.
- The riddle is challenging with clear, progressive hints, and suitable complexity.
- The riddle is perfectly balanced, challenging yet solvable with well-placed, fair hints and appropriate complexity.
When this eval is executed, a score of 1-5 will be assigned. If a scaled score is not appropriate, you may also create Pass/Fail evals as well. In fact, in many cases a Pass/Fail eval will perform better, so consider whether your criteria can be worded so that a Pass/Fail response is appropriate.
Auto-generating Criteria
By default, Libretto creates LLM-as-Judge evals automatically when a new prompt is created. However, if a prompt doesn't have any LLM-as-Judge evals you'll have the opportunity to instruct Libretto to auto-generate them. This is a great way to quickly get started with LLM-as-Judge, but you may want to fine tune the criteria after generation!
- Simply click the "Auto-generate evaluations" button. Libretto will generate up to five criteria for you, all of which should be relevant to the current prompt template.
Manually Creating Criteria
- Click the "+ Add evaluation" button.
- Write your own criteria by describing what you want the LLM-as-Judge to evaluate.
- Choose a scoring option:
- Pass/Fail: useful if the assessment is always discretely binary.
- Scale 1-5: appropriate when the assessment can be continuous in nature.
- Save the criteria.
Grading & Calibration
The nature of LLM-as-Judge evals is that they are typically subjective, which inevitably means that humans can/will disagree with certain assessments. Libretto provides a way to improve the human/LLM alignment through a grading and calibration process.
This generally works as follows:
- LLM-as-Judge evals are created (either automatically or by hand).
- A test is run for the prompt, triggering the LLM-as-Judge evals to execute and record scores for each test case.
- A human assigns grades for each test case, completely independently of the LLM-as-Judge.
- Libretto analyzes the differences between the human grades and the LLM grades, then attempts to improve the eval such that the human/LLM alignment is as close as possible.
To begin this workflow:
- Ensure that your prompt template has test cases and LLM-as-Judge evals
- Run a test via the Playground
- Once the test completes, navigate to the test results page where you'll be able to see the scores that the LLM assigned.
- Click the "Grade Scores" button:

- Go to the "Grade Responses" tab and assign your own grades to as many test cases as possible:
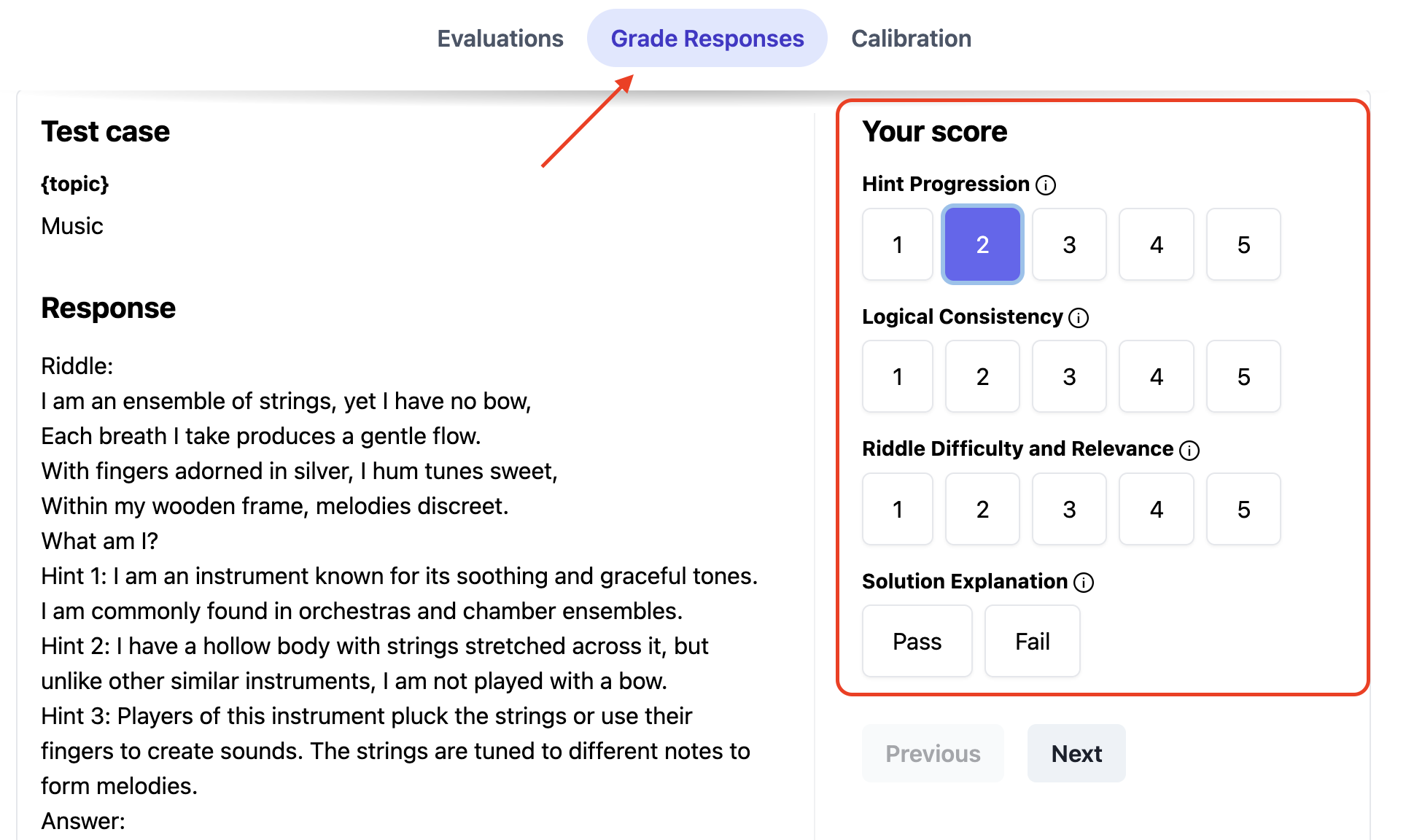
- Once at least 10 scores have been submitted, calibration can be started:
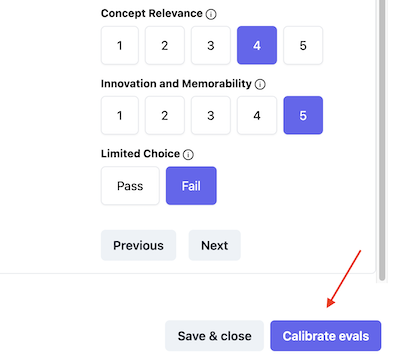
- Let the calibration finish, after which you will be shown the new human/LLM alignment scores that indicate how closely your grades match with the LLM-as-Judge grades.